スポンサードリンク
※ この記事は、「正規表現」の知識と「コンパイラの処理の流れ」について軽く理解してから読むことをおすすめします。もし正規表現やコンパイラの処理の流れの知識について自信がない人は、下の記事にて復習をすることをおすすめします。
[記事1] うさぎでもわかるオートマトンと言語理論 第09羽 正規表現と有限オートマトン
[記事2] うさぎでもわかる計算機システム Part11 コンパイラの処理の流れ(字句解析と意味解析のしくみ)
こんにちは、ももやまです。
皆さんが書いたプログラム(C言語など)が実際にコンピュータ上で実行できる形(機械語)にするためには、「コンパイル」をする必要があるのでしたね[1] … Continue reading。
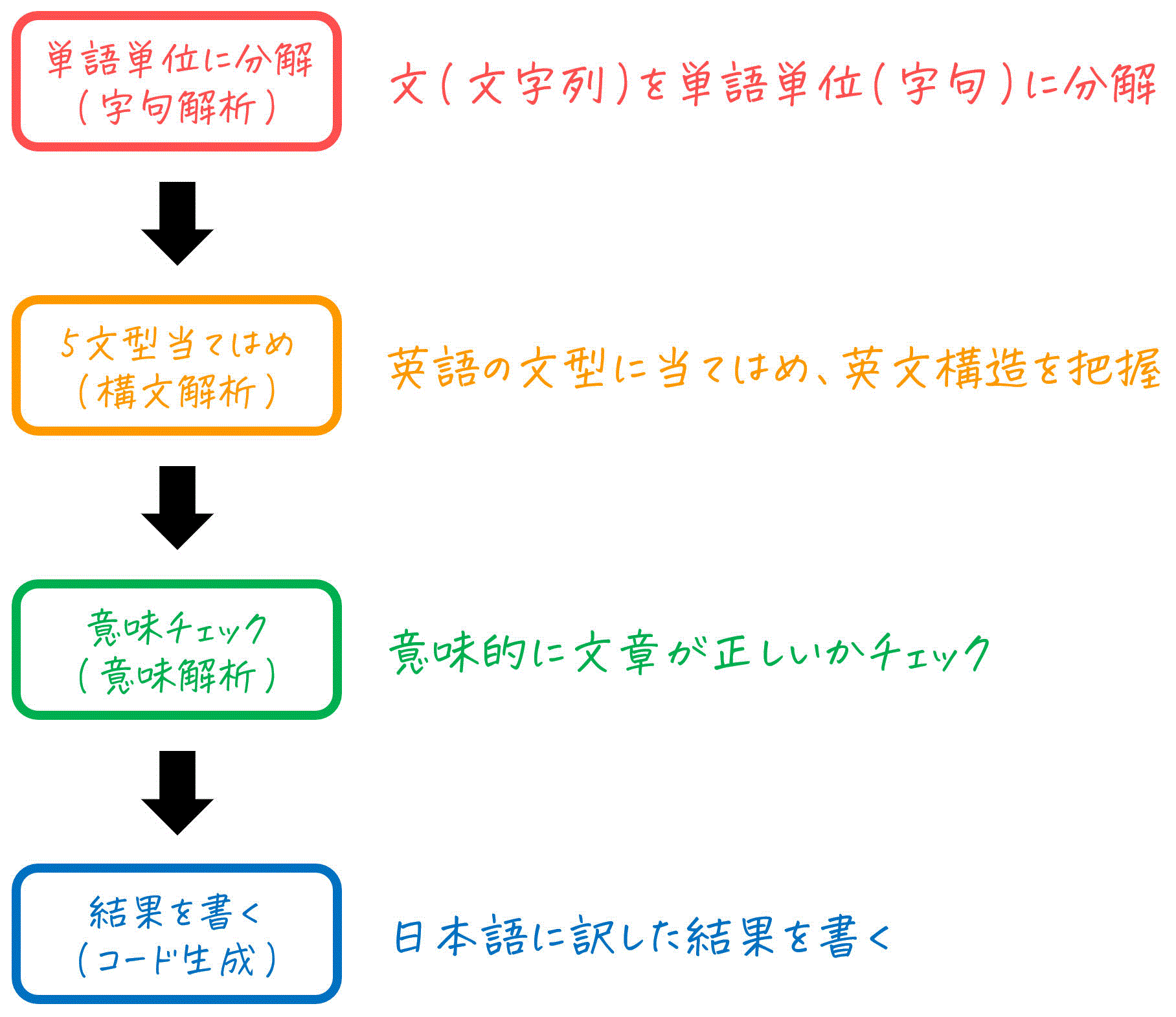
この「コンパイル」の流れ(C言語が機械語になるまでの過程)ですが、大まかに分けると下の4つに分けることができます。
今回は、上の4つの過程の中でも最初の「字句解析」を実際に体験することができるLex(Flex)の読み方や書き方について見ていきます。
※ FlexはLexの上位互換みたいなもので、基本的な使い方などはLexと同じです。そのため、Flexについて知りたい人もこの記事をご覧いただいてOKです。
(具体的にFlexとLexがどう違うのかはこの記事では割愛します。)
目次
スポンサードリンク
1. 字句解析ってなに?[復習]
Lexについて勉強する前に、字句解析ではどんなことをするかを軽く復習しておきましょう。
皆さんは「英語で書かれた文章を日本語に直しなさい」という作業を英語の期末試験やら入試でやったことがあると思います。
そのときに、英文に出てくる各英単語が「どんな品詞を持って、どんな意味を持つのか」を考えながら翻訳していたと思います。

コンパイラの世界でも、C言語(のような高級言語)をコンピュータが実行できる言語に翻訳する1つ目のステップとして、C言語で書かれたファイルの文字列を、単語単位に分割していき、その単語の属性(英語でいう品詞)がどれにあたるのかを機械的にチェックしていきます。
このファイル内の文字列を単語単位に分割し、分割した単語(字句と呼びます)がどの属性(例: 識別子、キーワード、定数、文字列、etc...)にあたるのかをチェックしていく過程が字句解析なのです!
※ 属性というのはあまり一般的な言い方ではありませんが、わかりやすく表現するために本記事では属性という表現を使っています。
スポンサードリンク
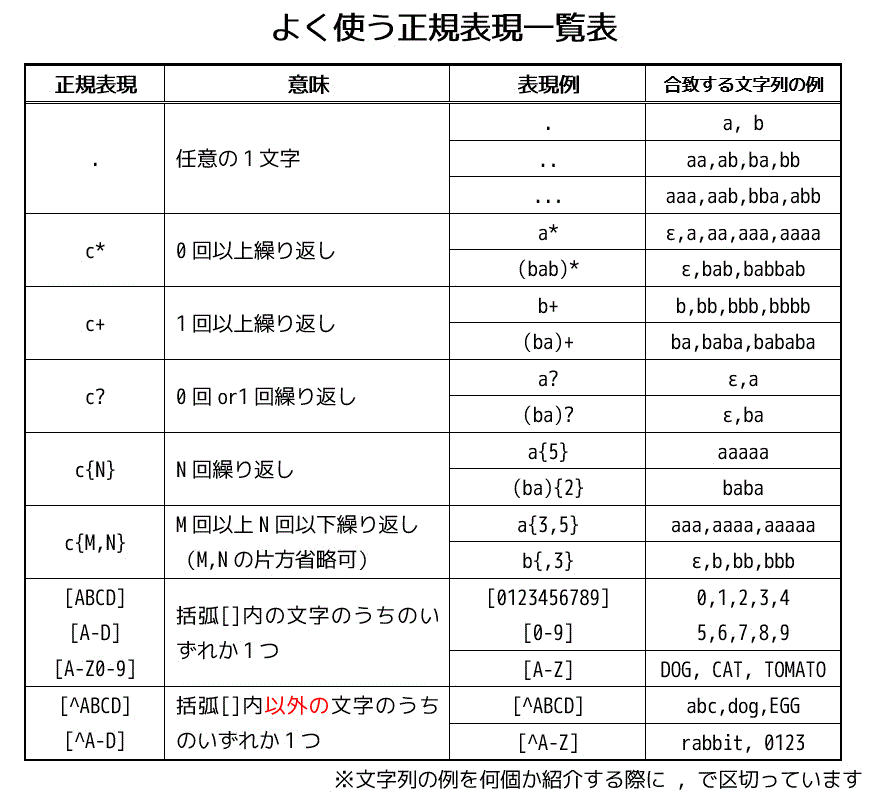
2. 正規表現 [復習]
字句解析では、ファイル内の文字列を字句ごとに分割したあとに、「それぞれの字句がどの属性(識別子、キーワード、定数、文字列、etc...)」に分類する際に、字句の属性ごとに「この文字列だったらこの属性になるよ~」というのを列挙します。
言い換えると、各属性ごとに「文字列を列挙した集合[2]文字列が集まった箱のようなものだと思ってください。」を用意し、ファイル内の文字列を分割した書く字句ごとにどの集合に属するかを調べていくことをします[3]各字句がどの属性の文字列集合(文字列が集まった箱か)に属するかを調べていくかというのを考えます。。
しかし、文字列を列挙した集合を作る際に、特定の文字列を指定するだけならともかく、「最初の1文字目はアルファベット、2文字目以降はアルファベット or 数字の文字列」のような指定の仕方をする場合、いちいち該当する文字を1文字1文字列挙していっては何日たっても列挙が終わりません。
ここで出てくる魔法のテクニックが正規表現です。正規表現では「最初の1文字目はアルファベット、2文字目以降はアルファベット or 数字の文字列」のように一定のルールに従った文字列を(いちいち列挙することなく)1単語ですべて表現することができます。
ここからは、Lexでよく使う正規表現をサクッと復習していきましょう。
(1) 繰り返しを表す記号
(1-a) 0回以上の繰り返し *
* をつけた直前の文字を0回以上繰り返します。
例: smo*ch の場合に当てはまる文字列の例
- smch
- smoch
- smooch
- smoooch
- smoooooooooooooooooooooooooooooooch
(1-b) 1回以上の繰り返し +
+ をつけた直前の文字を1回以上繰り返します。
例: smo+ch の場合に当てはまる文字列の例
- smoch
- smooch
- smoooch
- smoooooooooooooooooooooooooooooooch
smo+ch と列挙した場合、smch は + の直前の文字列oを1回も繰り返していないため、当てはまらない。
(1-c) 0回もしくは1回の繰り返し ?
? をつけた直前の文字を0回 or 1回繰り返します。
例: smo?ch の場合に当てはまる文字列
- smch
- smoch
※ この2種類以外の文字列は当てはまらない
(1-d) 特定回数の繰り返し {min,max}
{min,max} をつけた直前の文字列を min 回 ~ max 回の間繰り返します。
※ min, max のどちらか片方は省略可能です。
例1: smo{2,4}ch の場合に当てはまる文字列 (min = 2, max = 4)
- smooch
- smoooch
- smooooch
※1 {2,4}をつけた直前の文字列 o を2~4回繰り返しているものだけが当てはまる
※2 この3種類以外の文字列は当てはまらない
例2: smo{,3}ch の場合に当てはまる文字列 (min = 指定なし, max = 3)
- smch
- smoch
- smooch
- smoooch
※1 {,3}をつけた直前の文字列 o を3回以下繰り返しているものだけが当てはまる
※2 この4種類以外の文字列は当てはまらない
例3: smo{3,}ch の場合に当てはまる文字列の例 (min = 3, max = 指定なし)
- smoooch
- smooooch
- smoooooch
- smoooooooooooooooooch
※ {3,}をつけた直前の文字列 o を3回以上繰り返しているものだけが当てはまる
(2) 文字列を指定する表現
(2-a) グループ化のカッコ ( )
文字列を ( ) すると、カッコ内の文字列をグループ化することができます。
(1)で説明した「繰り返しを表す記号」で使われます。
例: (usa)+dayo の場合に当てはまる文字列の例
- usadayo
- usausadayo
- usausausadayo
※ usaで1グループなので、usaudayo のように、usa単位で繰り返しをしていない文字列は当てはまらない
(2-b) いずれかを表す記号 | ※ ( ) と同時に使用OK
複数パターンの文字列を当てはめる場合に使います。
例1: center|centre の場合に当てはまる文字列
- center
- centre
例2: cent(er|re) の場合に当てはまる文字列
- center
- centre
※ 基本的には、例2のように複数パターン当てはまる部分だけを ( ) と | を使って表すことが多い。
(2-c) 1文字単位で当てはまる文字を指定する記号 [ ]
カッコ [ ] を使うと、カッコ内で指定した文字が当てはまるようになります。
※ カッコ単体ではあまり使わず、他の文字列や記号、繰り返しを組み合わせて使うのが基本です。
例1: [ABC] の場合に当てはまる文字列(文字?)
- A
- B
- C
例2: [01]+ の場合に当てはまる文字列の例
- 0
- 1
- 00
- 01
- 10
- 11
※ [01]+ は、0, 1だけが出てくる1文字以上の文字列がすべて当てはまる
例3: 00[01]* の場合に当てはまる文字列の例
- 00
- 000
- 001
- 0000
- 0001
- 0010
- 0011
※ 「00」 or 「00が最初に来たあとに、0もしくは1だけが続く」文字列が当てはまります。
(2-d) 1文字の指定 [ ] をする際の省略記法 -
複数文字を指定する際に、ASCIIコード的に連続している文字を指定する場合は下のように省略記法 - を使うことができます。
[表記例]
- [A-Z] → アルファベット大文字を指定
- [a-z] → アルファベット小文字を指定
- [A-Za-z] → アルファベットを指定
- [0-9] → 数字を指定
- [A-Za-z0-9] → アルファベット or 数字を指定
実際の使用例も何個か見てみましょう。
例1: [A-C] の場合に当てはまる文字列(文字?)
- A
- B
- C
※ [A-C] は [ABC] と同じ
例2: [0-9]+ の場合に当てはまる文字列の例
- 3
- 0124151
- 534290
- 52309432865
※ [0-9]+ は、数字が1文字以上繰り返されるのを表す
(2-e) 任意の1文字を表す記号 .
. は1文字であればどんな文字でもOKです。
(ワイルドカード的な効果を持つと思っていただけたらOKです)
例1: usa.iの場合に当てはまる文字列の例
- usaai
- usagi
- usa#i
例2: .+の場合に当てはまる文字列の例
- a
- ohayo
- hello
- nihao
- annyonghaseyo
※ 1文字以上の文字列すべてがすべて当てはまります
これで、Lexで使う知識の復習は完了です。いよいよLexの中身に入っていきましょう。
スポンサードリンク
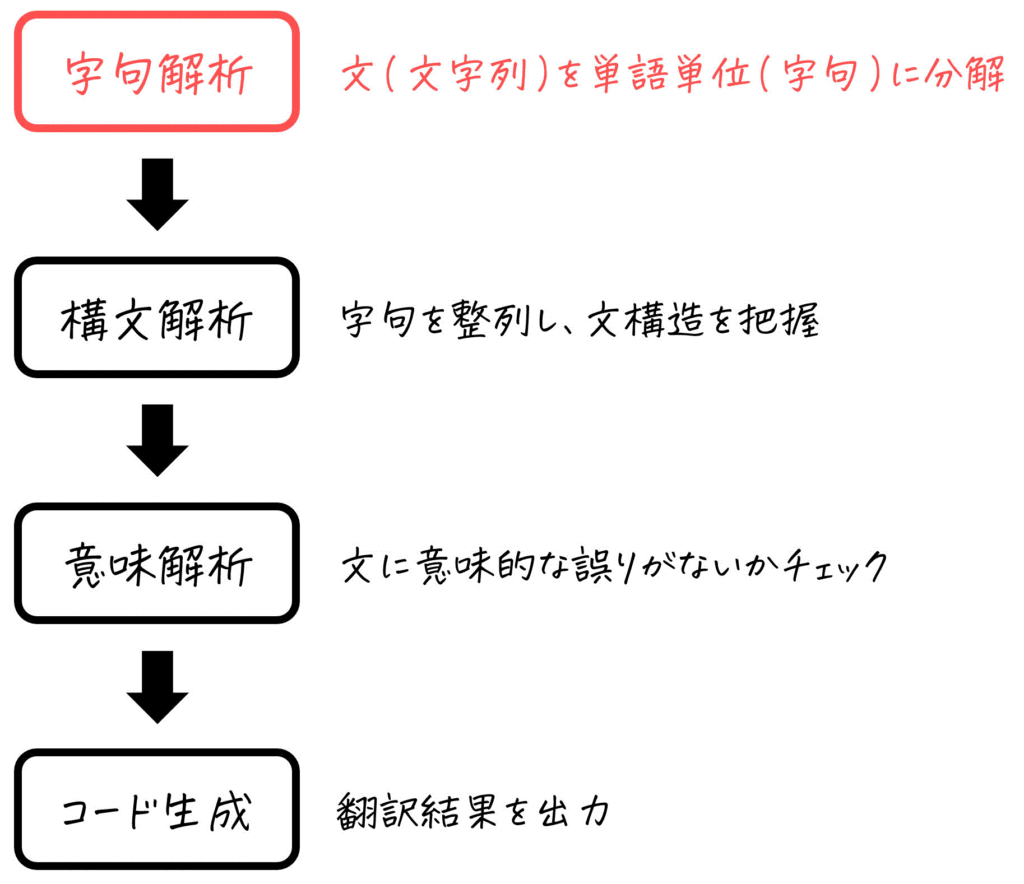
3. Lex(Flex)の書き方(構造)
Lexプログラムの構造としては「定義部」、「規則部(ルール部)」、「ユーザー定義サブルーチン部」の3層構造となっており、拡張子は .l で表されます。

それでは、「定義部」、「規則部(ルール部)」、「ユーザー定義サブルーチン部」で具体的にどのような内容が記述されるかを実際に見ていきましょう。
(1) 定義部 [省略OK]
「規則部」や「ユーザー定義サブルーチン部」で使う外部ヘッダファイルをインクルードしたり、外部変数を宣言する際に使います。
書き方としては、定義部の始点に %{ 、終点に %} を書き、その間に必要な外部ヘッダファイルのインクルードや外部変数の宣言をC言語で行います。
%{ // 定義部スタートは必ず %{
#include <stdio.h> // 外部ヘッダファイル読み込み
int alphabet_capital = 0; // 外部変数
int alphabet_small = 0;
int number = 0;
int others = 0;
// 定義部の終わりは必ず %}
%}
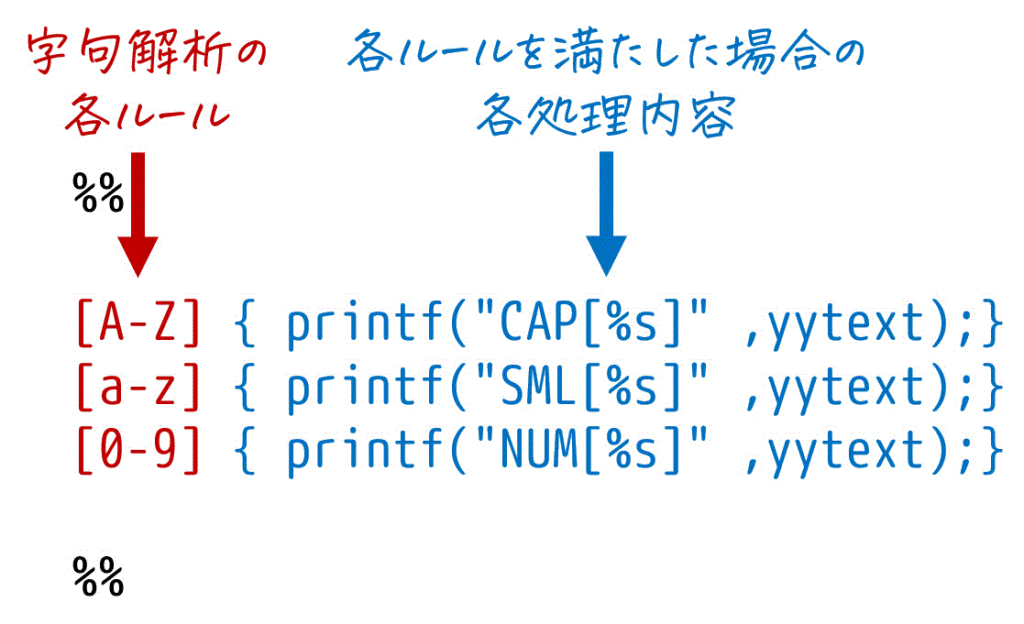
(2) 規則部(ルール部)
字句解析の規則を記述するLexの心臓部分で、Lexで最も重要な箇所です。
書き方としては、まず規則部の始点と終点に %% を書き、その間に「字句解析のルール」と、「ルールを満たしたときに処理される内容(C言語で記述)」を書きます。

lex限定の変数 - yytextとyyleng
ルールを満たしたときに処理される内容を括弧内 { } にC言語で記述する際に、Lex専用の変数 yytext, yychar を使うことができます。変数の特性は、下の通りです。
yytext→ ルールを満たしたとき、どの文字列でルールを満たしたかを文字列の形で表すyyleng→yytextの文字列の長さを表す
[例] 文字列 ABABC がルール [A-Z]+ にマッチした場合
yytext→ABABCyyleng→5
(3) ユーザー定義サブルーチン部 [省略OK]
(2)の字句解析をした結果を利用したC言語プログラムを書くことができます[4]下の例は、main 関数しかありませんが、新たに自分自信で関数を定義することもできます。。
(1)の定義部と同じく省略することもできますが、省略しない場合はプログラム中の字句解析をする箇所に yylex(); を必ず書く必要があります[5] yylex(); を書かない場合、字句解析が行われずにプログラムが終了します。。
int main(void) {
yylex(); // ここで (2)規則部に従って字句解析が行われる
printf("英大文字:%3d文字\n",alphabet_capital);
printf("英小文字:%3d文字\n",alphabet_small);
printf("算用数字:%3d文字\n",number);
printf("その他 :%3d文字\n",others);
}
第4章からは、Lexの心臓部分である「規則部(ルール部)」に着目して、Lexでの字句解析の動きを見ていきましょう。
4. Lexの動きを見てみよう(基本編)
規則部では、入力した文字列を「規則部内に正規表現で書いた各ルール」に従って先頭から1文字ずつ字句解析をしていきます。しかし、正規表現に慣れている人にとっても、Lexでの字句解析は少し複雑です。
そこで、ここからは実際にLexを用いて字句解析をする場合、どのような動作をするのかを全6パターンを用いて説明していきます。
(1) レベル1 1文字を入力した場合
まずは、1文字だけを入力する一番カンタンなパターンで字句解析の仕組みを把握しましょう。
3章で軽く説明した通り、規則部には「字句解析の各ルール」と「各ルールを満たした場合の各処理内容」が列挙されているのでしたね。
例えば、入力として A という文字列が来た場合を考えましょう。

A が来たときに満たすルールと処理内容A という文字列は、各ルールの中の一番上のルール [A-Z] にマッチしますね。そのため、[A-Z] の右側にかかれている
printf("CAP[%s]",yytext);
が実行され、CAP[A] というのが出力されます。
※ 規則部の出力で yytext と書くと、ルールにマッチした部分の文字列が出力されます。(今回の場合は A が出力される)
では、9 という文字列が来た場合、上から何番目の規則にマッチして何が出力されるでしょう? 少し考えてみましょう。
%%
[A-Z] { printf("CAP[%s]",yytext); }
[a-z] { printf("SML[%s]",yytext); }
[0-9] { printf("NUM[%s]",yytext); }
%%
正解は、上から3番目のルールです。ですので、3番目のルール [0-9] 右側にかかれているprintfの内容
printf("NUM[%s]",yytext);
が実行され、NUM[9] が出力されますね。

(2) レベル2 複数文字入力した場合
今度は、複数文字入力した場合を見ていきましょう。
複数文字を入力した場合、文字列の終点にたどり着くまで1文字目から順番にマッチする文字列を探していきます。
例えば、先程と同じ規則部を持つLexファイルに対して、AbB3 を入力した場合、出力がどうなるかをアニメーションで追ってみましょう。
%%
[A-Z] { printf("CAP[%s]",yytext);}
[a-z] { printf("SML[%s]" ,yytext);}
[0-9] { printf("NUM[%s]" ,yytext);}
%%
[アニメーション]

よって、出力内容が
CAP[A]SML[b]CAP[B]NUM[3]
となることがわかります。
(3) レベル3 どのルールにも当てはまらない場合
Lexで字句解析を行う際に「どの規則にも当てはまらない文字列」が出てきた場合、どのような動きをするかも確認しておきましょう。
例えば、下の規則に文字列 A3b を入力することを考えます。
%%
[A-Z] { printf("CAP[%s]",yytext);}
[a-z] { printf("SML[%s]",yytext);}
%%
すると、最初の1文字 A までは CAP[A] と順調に規則にマッチするのですが、2文字目〜4文字目の 3, 3, 4 にマッチする規則はありません。
このようにマッチする規則がない場合は、入力した文字がそのまま出力されます。そのため、CAP[A] に引き続き、入力した 334 が出力されます。
ただし最後の5文字目は、上から2番目の規則にマッチするため、SML[b] が CAP[A]334 に引き続き出力されます。
よって、最終的な出力は CAP[A]334SML[b] となります。

5. Lexの動きを見てみよう(応用編)
4章の基本編では、規則部の動きを確認するために、文字列を1文字ずつ字句解析させていき、その動きを確認しました。
この応用編では少しレベルを上げて、複数文字をマッチできるルールを入れたときの字句解析させたときのプログラムの動きを確認しましょう。
(1) レベル4 複数文字のマッチが可能な場合の動き
例えば、次の規則部を持つLexプログラムに対して、1423DB と入力することを考えましょう。
%%
[A-D] { printf("CAP[%s]" ,yytext);}
"3D" { printf("3DD[%s]" ,yytext);}
1[0-9]+ { printf("NUM[%s]" ,yytext);}
. { printf("???[%s]" ,yytext);}
%%
まず、最初に上から3番目のルール 1[0-9]+ とマッチします。ここで、1[0-9]+ というのは、「1で始まり、その後に0~9が1文字以上続く文字列」を表します。そのため、
- 1だけマッチさせる
- 14までマッチさせる
- 142までマッチさせる
- 1423までマッチさせる
のどのパターンでも3番目のルールを適用させることが可能です。
このようなパターンの場合、Lexは(ルールを満たす中で)マッチする文字数が最も多くなるパターンを選択します[6]難しい言い方をすると、yytext に入る文字数が最も多くなる(=yyleng が最大になる)パターンを選択するとも言えます。。そのため今回の場合は、1423まで 1[0-9]+ のルールでマッチします。

※ 残りの2文字D, Bは、それぞれ [A-D] のルールに1文字ずつマッチさせられるので、 NUM[1423] に引き続いて CAP[D]CAP[B] と出力されます。
(2) レベル5 適用できるルールが複数ある場合の動き
例えば、下のLexプログラムに対して、CCSakura と入力することを考えましょう。
※ Lexでは上から3番目のルール CC のように、マッチさせる文字列を "CC" のようにダブルクオーテーション "" で囲んで示すことができます
%%
[A-Z] { printf("CAP[%s]" ,yytext);}
[a-z]+ { printf("SML[%s]" ,yytext);}
"CC" { printf("CCC[%s]" ,yytext);}
%%
まず、最初にどの規則をマッチするかを考えましょう。すると、
- 一番上の規則
[A-D]でCとマッチ(1文字分マッチ) - 一番下の規則
"CC"でCCとマッチ(2文字分マッチ)
のどちらかを適用できそうですね。
このように適用できるルールが複数ある場合は、より長い文字数分マッチする規則が優先して適用されます。言い換えると、適用可能なルールの中で、マッチする文字列の文字数が最も長くなるようなルールが適用されます。
そのため、最小に適用される規則は「一番下の規則 "CC" が優先され、CCC[CC] が出力」されます。
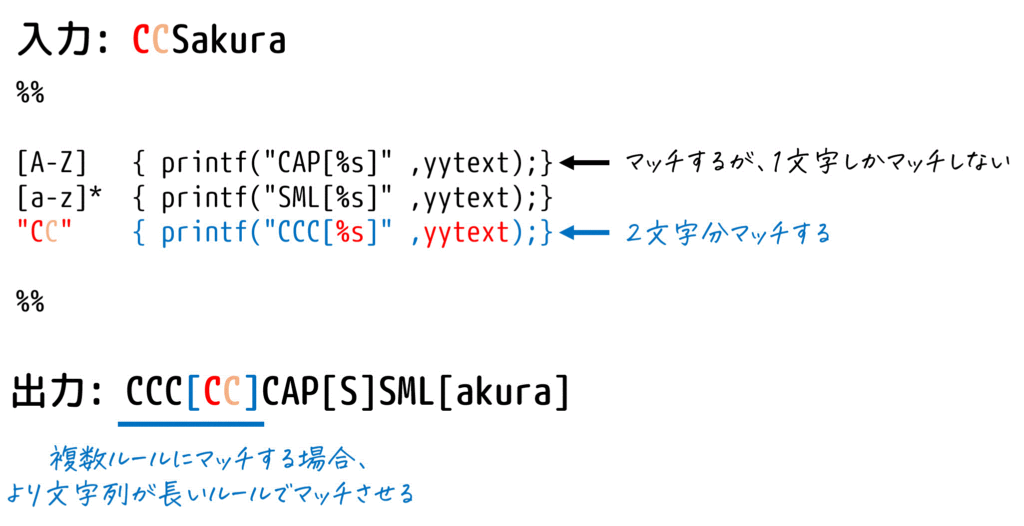
※ 残りの文字列Sakuraは、順番に
- 上から1番目の規則
[A-Z]→Sをマッチ - 上から2番目の規則
[a-z]+ →akuraをマッチ
と適用できるため、CCC[CC] に引き続いて CAP[S]SML[akura]と出力されます。
(3) レベル6 適用できるルールが複数 & マッチする文字列が最長となる規則が複数ある場合
適用できるルールが複数ある場合は、「マッチする文字列の文字数が最も長くなる規則」が優先して適用されるのでしたね。
しかし、「マッチする文字列の文字数が最も長くなる規則」が複数ある場合が出てくる場合があり、文字列の長さだけではマッチさせるルールが決まらないことがあります。
例えば、下のLexプログラムに対して、C# と入力することを考えましょう。
%%
[A-Z] { printf("CAP[%s]",yytext); }
[a-z] { printf("SML[%s]",yytext); }
[0-9] { printf("NUM[%s]",yytext); }
. { printf("???[%s]",yytext); }
%%
まず、最初にどの規則をマッチするかを考えましょう。すると、
- 一番上の規則
[A-Z]でCとマッチ → 1文字マッチ - 一番下の規則
.でCとマッチ → 1文字マッチ
のどちらかを適用できそうですが、どちらの規則も「1文字分」しかマッチしません。
このように適用できるルールが複数あり、なおかつ「マッチする文字列の文字数が最も長くなる規則」が複数ある場合は、適用可能で最もマッチする文字列の文字数が長くなるルールのうち、最も上に書かれているルールが適用されます。
今回の場合、より上にかかれている1番上の規則 [A-Z] が適用されるため、出力は CAP[C] となります。

※ 残りの文字列 # は、一番下の規則以外満たさないため、CAP[C] に引き続いて ???[#] が出力されます。
規則部内に複数適用できるルールがある場合、つぎの1, 2の優先順で適用するルールを決める。
- より多くの文字列をマッチさせることができるルール
- より上側に記載されているルール
6. 練習問題 (Lexの動きを確認しよう)
それでは、規則部の動きについて理解できているかどうかを、練習問題を通じて確認しましょう。
問題.
以下のLexプログラム(規則部以外は省略されている)に、(1)〜(4)の文字列をそれぞれ入力したときの出力を答えなさい。
%%
[0-1][0-9]+ { printf("OP1[%s]",yytext); }
[A-C]+0* { printf("OP2[%s]",yytext); }
"3C" { printf("OP3[%s]",yytext); }
"B1" { printf("OP4[%s]",yytext); }
"#"|"@" { printf("OP5[%s]",yytext); }
. { printf("???[%s]",yytext); }
%%
(1) 0120
(2) 3CA#@
(3) ABC02
(4) B197
解答.
それぞれのルールを日本語に直すと下のようになります。
[0-1][0-9]+→ 最初に0 or 1、その後に1文字以上数字が来ればマッチ[A-C]+0*→ A, B, Cのいずれかが1文字以上来ればマッチ。A, B, Cが1文字以上続いたあとに0が続く文字列でもマッチ。"3C"→ 3C だけマッチ。それ以外の文字列にはマッチしない。"B1"→ B1 だけマッチ。それ以外の文字列にはマッチしない。"#"|"@"→ # もしくは @ が来たときにマッチ。.→ 任意の1文字にマッチ
これを踏まえて、(1)〜(4)の出力を考えていきましょう。
(1) 入力: 0120
文字列0120は、一番上の規則
[0-1][0-9]+ { printf("OP1[%s]",yytext); }
に全てマッチできますね。(0120 → [0-1][0-9]+)
そのため、出力は OP1[0120] となります。
(2) 入力: 3CA#@
まず、最初の2文字 3C は上から3番目の規則
"3C" { printf("OP3[%s]",yytext); }
にマッチします。(出力: OP3[3C] )
つぎに、3文字目 A が上から2番目の規則
[A-C]+0* { printf("OP2[%s]",yytext); }
にマッチします。(出力: OP2[A] )
※ 上から6番目の規則 . にもマッチしますが、より上にかかれている規則にもマッチするため、上から2番目の規則が優先的に選ばれます。
つぎに、4文字目 # が上から5番目の規則
"#"|"@" { printf("OP5[%s]",yytext); }
にマッチします。(出力: OP5[#] )
※ 上から6番目の規則 . にもマッチしますが、より上にかかれている規則にもマッチするため、上から2番目の規則が優先的に選ばれます。
最後に5文字目 @ も上から5番目の規則
"#"|"@" { printf("OP5[%s]",yytext); }
にマッチします。(出力: OP5[@] )
※ 上から6番目の規則 . にもマッチしますが、より上にかかれている規則にもマッチするため、上から2番目の規則が優先的に選ばれます。
よって、3CA#@ を入力したときの出力内容は OP3[3C]OP2[A]OP5[#]OP5[@] となります。
(3) 入力: ABC02
まず、最初の4文字 ABC0 まで上から2番目の規則
[A-C]+0* { printf("OP2[%s]",yytext); }
にマッチします。(出力: OP2[ABC0] )
つぎに、最後の1文字 2 が一番下(上から6番目)の規則
. { printf("???[%s]",yytext); }
にマッチします。(出力: ???[2] )
よって、ABC02 を入力したときの出力内容は OP2[ABC0]???[2] となります。
(4) 入力: B197
まず、最初の2文字 B1 までは上から4番目の規則
"B1" { printf("OP4[%s]",yytext); }
にマッチします。(出力: OP4[B1] )
[A-C]+0* { printf("OP2[%s]",yytext); }
にマッチするのでは? と思った人もいるかもしれませんが、上から2番目の規則 [A-C]+0*の場合、最初の1文字 B にしかマッチしないため、より多くの文字列をマッチできる上から4番目の規則 "B1" が優先的に選ばれます。
つぎに、3文字目の9、4文字目の7は上から6番目の規則
. { printf("???[%s]",yytext); }
に1文字ずつマッチします[7]上から1番目の規則 (0始まりの2桁以上の数字でないと受理しない)と間違えないように注意!。そのため、OP4[B1] に引き続いて ???[9]???[7] とマッチします。
よって、B197 を入力したときの出力内容は OP4[B1]???[9]???[7]
[おまけ] 実際にLexを動かしてみよう! (Mac・Linux)
最後に、実際にコンピュータ上でLexプログラムを動かしてみましょう!
※ Mac・Linuxユーザーの人は何もインストールすることなく、Lexを使うことができます。
Windowsの人も「Flex for Windows」などをインストールをすればLexを動かすことは可能ですが、少し手順がめんどくさいです。)
Step1. Lexプログラムを作成する
まずは、テキトーなエディタを開き、下のプログラムを貼り付けて debt.l という名前で保存してください。(練習問題と同じプログラムです)
%%
[0-1][0-9]+ { printf("OP1[%s]",yytext); }
[A-C]+0* { printf("OP2[%s]",yytext); }
"3C" { printf("OP3[%s]",yytext); }
"B1" { printf("OP4[%s]",yytext); }
"#"|"@" { printf("OP5[%s]",yytext); }
. { printf("???[%s]",yytext); }
%%
保存し終わったら、ターミナルを開き、つぎの2つのコマンドを上から順番に1つずつ打ってください。
※ 何かしらのwarningが出た場合でも無視してOKです。エラーが出た場合は貼り付けが正しくできているかを確認してください。
lex lex_pattern1.l
cc lex.yy.c -ll
すると、Lexファイルがコンパイルされ、実行ファイル a.out ができます。あとはこの a.out を実行すればOKです。
./a.out
実行すると、「文字列の入力を待機している状態」になります。
(何もメッセージが出ていないからといって、応答なし状態になっているわけではないのでご安心ください。)
試しに、3CA#@ と入れてEnterと押してみましょう。(練習問題(2)と同じ文字列です)
すると、練習問題(2)の解答と同じ文字列が出力されるはずです…!
OP3[3C]OP2[A]OP5[#]OP5[@]
※ 出力された場合はLexで実際に字句解析させることに成功しました!
8. さいごに
今回は、実際にLexプログラムを使って(ポインタや文字列操作のような複雑なC言語の知識を使うことなしに)字句解析を体験していきました。
次回からは、構文解析について数回に分けて学習していきましょう!
注釈
| ↑1 | 中には、PythonやRubyのように、コンパイラを用いて機械語に翻訳せず、書いたプログラムを解釈しながら(インタプリタを用いて)実行していく言語もあります。 |
|---|---|
| ↑2 | 文字列が集まった箱のようなものだと思ってください。 |
| ↑3 | 各字句がどの属性の文字列集合(文字列が集まった箱か)に属するかを調べていくかというのを考えます。 |
| ↑4 | 下の例は、main 関数しかありませんが、新たに自分自信で関数を定義することもできます。 |
| ↑5 | yylex(); を書かない場合、字句解析が行われずにプログラムが終了します。 |
| ↑6 | 難しい言い方をすると、yytext に入る文字数が最も多くなる(=yyleng が最大になる)パターンを選択するとも言えます。 |
| ↑7 | 上から1番目の規則 (0始まりの2桁以上の数字でないと受理しない)と間違えないように注意! |
関連広告・スポンサードリンク