スポンサードリンク
こんにちは、ももやまです。
今回は、C言語における文字列型についてのまとめを行います。
目次
スポンサードリンク
1.文字列型 char
int型、double型、float型などは数字を記憶しておく変数でしたね。
しかし、数字以外に文字などを記憶しておきたいときがありますね。
しかし計算機上では0,1の2進数以外ではデータを記録することができません。
そんなときに使うのがchar型です。char型は -128 ~ 127までの1バイト(8ビット)の数字を記録しておくことができます。
C言語では、範囲の中の0~127のそれぞれの数字と文字を対応づけることで、文字を記憶することを実現しています。
スポンサードリンク
2.ASCIIコード
さきほど説明した数字と文字の対応付けが計算機によって異なっていたりすると大変不便ですね。
なので、C言語ではアスキーコード(ASCIIコード)を使うことで計算機による数字と文字の対応付けを共通化し、(数が同じなのに)計算機によって異なる文字が出力されないようにしています。
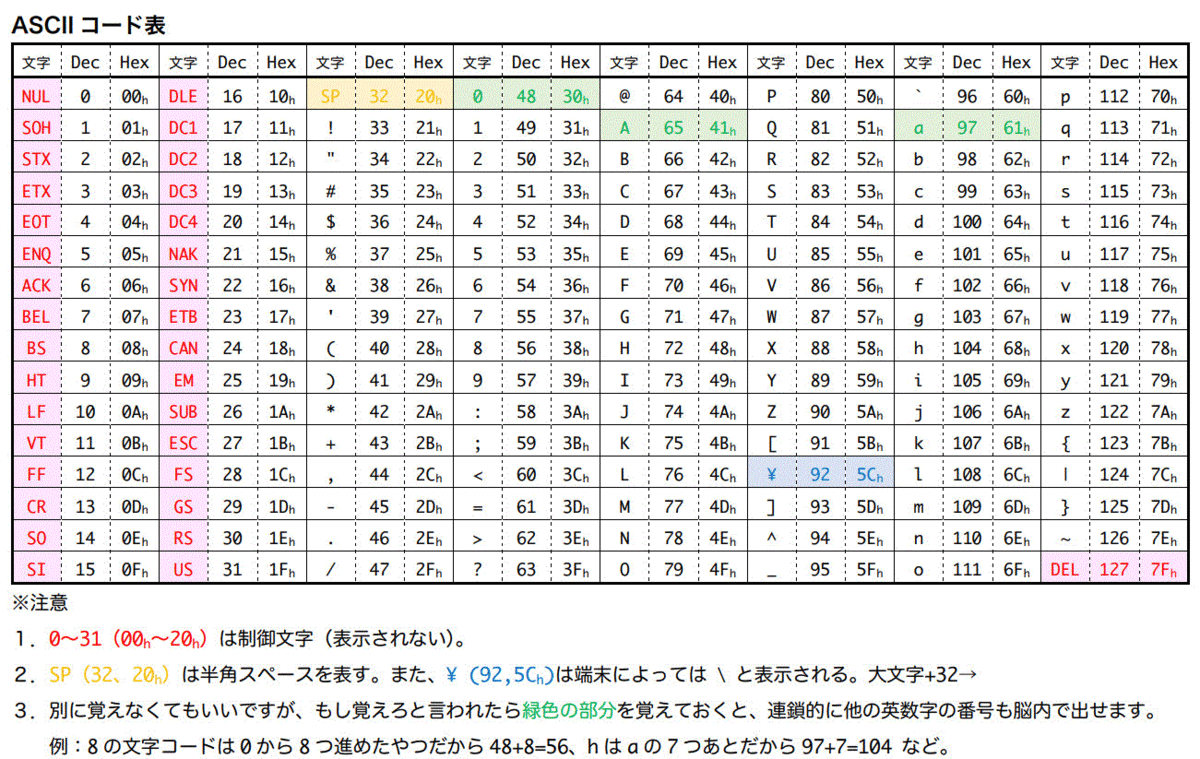
ASCIIコード表を下に示しておきます。
PDFでも用意したので欲しい方はこちらからダウンロードをお願いします。

なお、このASCIIコードはもちろん全部覚える必要がありません。
覚えるのであれば、
- 0〜9が連番になっていること
- 大文字に32を足すと小文字に、小文字に32を引くと大文字になること
- アルファベットのA〜Z, a〜zは連番になっている
- 文字列の0のコードは48(30h)、Aは65(41h)、aは97(61h)
くらいは覚えていたらもしかしたら役に立つかもしれません。
スポンサードリンク
3.文字の代入・演算
では、実際に文字を代入したり演算したりしてみましょう。
#include<stdio.h>
int main(void) {
char code = 70; // もちろん数字も代入できる
char moji = 'f'; // ` ` と囲むと文字も代入できる
printf("Moji1: %c\n",code); // 文字コード70→ `F`
printf("Code1: %d\n",moji); // `f` → 文字コード102
code += 5; // Fの5つ先の文字はK
moji -= 32; // 小文字から32を減算すると大文字へ
printf("Moji2: %c\n",code);
printf("Moji3: %c\n",moji);
// 条件式などにも文字を指定可能
if(code < 'I') { // Iの文字コードは73なので、code < 73 と同じ
moji += 2;
}
else {
moji -= 2;
}
printf("Moji4: %c\n",moji); // 何が出力されるか予想してみよう!
return 0;
}
main関数の最初で code に70を代入していますね。
これは、文字コード70の文字 F を代入するのと同じことになります。
次の行では文字 f を代入していますね。' 'で囲むことで文字を直接代入することができます。
f の文字コードは102なので、この行は、
char moji = 102;
と同じです。
また、%c と書くと、文字コードに該当する文字を返します。
また、文字型配列の変数も他のint,double型の変数と同じように計算させたり、if文で数字、文字と比較することもできます。
このプログラムの実行結果としては、
Moji1: F Code1: 102 Moji2: K Moji3: F Moji4: D
となります。
また、文字列の演算を生かして、つぎのような関数を作ることもできます。
その1:文字型数字が与えらえたとき、それをint型の数字に直す関数 parseInt
int parseInt(char moji) {
return moji - '0';
}
その2:アルファベットの大文字を小文字に、小文字を大文字に、それ以外をそのままにする関数 changeUpLow
char changeUpLow(char moji) {
if('A' <= moji && moji <= 'Z') {
return moji + 32; // 大文字は小文字に
}
else if('a' <= moji && moji <= 'z') {
return moji - 32; // 小文字は大文字に
}
else {
return moji; // それ以外はそのまま
}
}
4.文字列配列
C言語では、char型の配列を用いることで文字列を表現することができます。
文字列配列では、文字列の終端をあらわすのに \0 (NULL文字)を使います。
つまり、0番目の配列 ~ \0 がある配列までが出力されます。
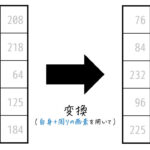
たとえば、文字列 Momoyama の場合、以下のように配列格納されます。

また、たとえ \0 以降に文字があったとしても、\0 以降の文字は出力されません。たとえば、文字列配列が

のように格納されている場合は、Momo としか出力されません。
複数の行の文字列を表現したい場合は改行記号 \n を使います。例えば、文字列配列

のように格納すると、
Usagi Suki
と2行にわたって表示させることができます。
では、実際に文字列型を使った配列のプログラムを使ってさらに文字列型配列に慣れていきましょう。
" " で文字列を囲むと文字列を直接代入することができます。
#include<stdio.h>
int main(void) {
#include<stdio.h>
int main(void) {
// 文字列を" " で囲むことにより初期値を代入
char mojiretsu1[8] = "Usamaru"; // '\0'を入れて合計8文字
char mojiretsu2[] = "Mafumafu"; // 要素数は指定しなくてもOK(最適な文字数が代入される)
char *mojiretsu3 = "Naranara"; // ポインタ変数で宣言してもOK
printf("%s\n",mojiretsu1); // 文字列は %s で出力
printf("%s\n",mojiretsu2); // ちゃんと出力されることを確認
printf("%s\n",mojiretsu3); // ちゃんと出力されることを確認
// 文字列書き換え
mojiretsu1[4] = 'u'; // 4番目の文字列をuに
mojiretsu1[2] = mojiretsu1[5] - 1; // 5番目の文字はr、-1なので1つ前の文字qが2番目に代入
printf("Line1:%s\n",mojiretsu1);
mojiretsu1[3] = '\0';
printf("Line2:%s\n",mojiretsu1); // '\0' 以降は無視
if(mojiretsu1[0] > mojiretsu1[1] - 32) { // U(85) > s(115) - 32 = 83 ?
printf("Moji1:%c\n",mojiretsu2[3]);
}
else {
printf("Moji2:%c\n",mojiretsu3[0]); // ポインタで宣言しても普通に配列として使える
}
return 0;
}
このプログラムを実行すると、
Usamaru Mafumafu Naranara Line1:Usqmuru Line2:Usq Moji1:u
となります。
ここからは、少し長いですがどうして上のような実行結果になるかの解説をしていきます。
まず、最初の3行の代入部分を見ていきましょう。char型の配列に文字列を代入する際には \0 を忘れないように注意しましょう。
今回の場合は、Usamaru(7文字) + \0 の合計8文字なので、配列の要素は8以上で宣言する必要があります。

2行目のようなmojiretsu2 のように配列の要素数を指定せずに宣言することや、mojiretsu3 のようにポインタのような形でも宣言することができます。この場合は、配列の要素数は自動的に適した数で宣言されます(今回の場合は9)。
なお、ポインタについては、こちらの記事に解説を書いているのでこちらもご覧ください。
つぎに3行の出力部分を見ていきましょう。printfなどによる文字列の出力は %s で行うことができます(stringの略)。いずれも宣言した通りの文字が出力されます。
つぎに文字列書き換え部分を見ていきます。最初の1行では配列の4番目(0番目から数えることに注意)を u に書き換えていますね。なので、mojiretsu1は、Usamaru から Usamuru に変わります。

その次の行は、配列の2番目に配列の5番目(r)から1を引いたものが代入されていますね。
rはASCIIコードで114ですね。そこから1を引いたものは113、つまりqですね。なので、配列の2番目にはqが代入*1されます。

なのでLine1のprintfの時点でmojiretsu1の中身は Usqmuru になりこれが出力されます。
Line2ですが、まずは配列の3番目に \0 が代入されていますね。
なので、配列の4番目以降の文字はすべて無視されます。

さいごにif文を見ていきましょう。
該当する配列の要素ASCIIコードを比べるとif文は真となるため、Mafumafu の3文字目であるuが表示されます。
4.文字列操作用のライブラリ関数
C言語では文字列を扱うために予め用意されている便利な関数があります。
文字列操作用のライブラリ関数を使うためには、ヘッダファイルを読み込むために最初に
#include<string.h>
を書く必要があります。
今回は文字列操作用のライブラリ関数の中でも個人的によく使うもの4つを紹介していきましょう。
その1: 文字列をコピーする strcpy
strcpy は文字列をコピーする関数です。
コピー先 to、コピー元 from の順番に引数を指定します。
*to = *from; // ×これだと to[0] = from[0] 相当(正しく文字列がコピーできない!)
strcpy(to,from); // ○これならコピー可!! 引数は コピー先、コピー元の順
実際に strcpy を使ったプログラムを1つ見てみましょう。
#include<stdio.h>
#include<string.h>
int main(void) {
char from[20] = "Momotaro";
char to[20] = "Momonosuke";
strcpy(to,from); // fromの文字列をtoにコピー
printf("%s\n",to); // Momotaro
return 0;
}
このプログラムを実行すると、
Momotaro
と表示され、正しくコピーされることがわかります。
その2: 文字列を連結する strcat
strcat は文字列を連結するライブラリ関数です。s1,s2 の順番に引数を指定することで、s1 に2つの文字列を連結したものを返します。
1つ使用例を見てみましょう。
#include<stdio.h>
#include<string.h>
int main(void) {
char s1[20] = "Momoyama";
char s2[20] = "Usagi";
strcat(s1,s2); // s1にs2の文字列をくっつける
printf("%s\n",s1); // MomoyamaUsagi
return 0;
}
このプログラムを実行すると、
MomoyamaUsagi
と表示され、正しく文字列が連結されることがわかります。
その3: 文字列の長さを表示する strlen
strlen は文字列の長さを返す関数です。
引数として文字列 s を指定すると、文字列 s の長さを返します。
実行例を見ていきましょう。
#include<stdio.h>
#include<string.h>
int main(void) {
char s1[20] = "Momoyama";
char s2[20] = "Usagi";
printf("LengthS1: %d\n",strlen(s1)); // 8文字
printf("LengthS2: %d\n",strlen(s2)); // 5文字
s1[3] = '\0'; // '\0'が文字列の終わりなのでそれ以降は無視
printf("LengthS1: %d\n",strlen(s1)); // 3文字
return 0;
}
実行結果は、
LengthS1: 8 LengthS2: 5 LengthS1: 3
となります。3行目の文字列が8ではなく3になっているのは、途中に \0 が入っているからです。
出力のときと同じく、\0 以降の文字は無視されます。
その4: 文字列の比較 strcmp
最後に文字列を比較する関数 strcmp となります。
この関数は、2つの文字列 s1 と s2 が等しい(もちろん大文字小文字は違うものとみなされる)かどうか判定し、等しければ0を、等しくなければ1か-1を返します[1] … Continue reading。
#include<stdio.h>
#include<string.h>
int main(void) {
printf("cmp1:%d\n",strcmp("apple","apple")); // 等しい
printf("cmp2:%d\n",strcmp("apple","banana")); //左側のほうが辞書順序で先
printf("cmp3:%d\n",strcmp("Momoyama","Mafumafu")); // 右側のほうが辞書順序で先
printf("cmp4:%d\n",strcmp("Momo","Momotaro")); // 比較する文字が含まれている場合は、長い方がより辞書式順序では後
return 0;
}
実行結果は以下のようになります。
cmp1:0 cmp2:-1 cmp3:14 cmp4:-116
cmp1は2つとも同じ文字列なので0が、cmp2は左側のほうが辞書式順序では先なので負の値が、cmp3は右側のほうが辞書式順序で先なので正の値*2が返ってきてますね。
5.練習
では、実際に文字列の操作が理解できているか1つ練習をしてみましょう。
少し長いですが、次のプログラムの実行結果を考えてみましょう。
#include<stdio.h>
#include<string.h>
int main(void) {
char str1[] = "Dashijiru";
char str2[100] = "Ikoma";
char *str3 = "Usagi";
printf("Code1:%3d\n",str1[5]);
str1[2] -= 16;
printf("Moji1:%c\n",str1[2]);
str1[5] = '\0';
if(str1[2] < 'c') {
str1[2] = str2[3];
}
else {
str1[2] = str3[3];
}
printf("Line1:%s\n",str1);
printf("Len1 :%d\n",(int)strlen(str1));
strcpy(str1,str2);
strcat(str2,str3);
printf("Line2:%s\n",str1);
printf("Line3:%s\n",str2);
if(strcmp(str2,"Ikomausagi") == 0) {
printf("Yes\n");
}
else {
printf("No\n");
}
return 0;
}
6.練習問題の答え
Code1:106 Moji1:c Line1:Dacoi Len1 :5 Line2:Ikoma Line3:IkomaUsagi No
解説を入れたプログラム
#include<stdio.h>
#include<string.h>
int main(void) {
char str1[] = "Dashijiru";
char str2[100] = "Ikoma";
char *str3 = "Usagi";
printf("Code1:%3d\n",str1[5]); // jの文字コード106を出力
str1[2] -= 16; // s(115) - 16 = 99 → [c]
printf("Moji1:%c\n",str1[2]); // Da[c]hijiruの2文字目はc。
str1[5] = '\0'; // 5文字目以降は無視
if(str1[1] < 'c') { // a(97) < c(99) なので True
str1[3] = str2[2]; // Ik[o]maのoをstr1の3文字目へ → Dac[o]i
}
else {
str1[3] = str3[2];
}
printf("Line1:%s\n",str1); // Dacoi
printf("Len1 :%d\n",(int)strlen(str1)); // 長さは5
strcpy(str1,str2); // 文字列str2をstr1にコピー(Dashijiruが入ってた配列は上書きされる)
strcat(str2,str3); // 文字列str2に文字列str3をくっつける ("Ikoma" + "usagi")
printf("Line2:%s\n",str1); // Ikoma
printf("Line3:%s\n",str2); // IkomaUsagi
if(strcmp(str2,"Ikomausagi") == 0) { // 大文字と小文字は違うものとして判定
printf("Yes\n");
}
else {
printf("No\n"); // 違うのでNoを出力
}
return 0;
}
7.さいごに
今回はC言語における文字(文字変数char)、文字列の表現法についてまとめました。
この記事を読んでC言語の文字、文字列の表現法などが少しでもわかっていただけたらありがたいです。
*1:配列の5番目から1を引くは、rのアルファベット順の1つ前(q)が代入されると考えてもOK
*2:ちなみに値は、「左(0番目)から順番に文字の比較を行い、違う文字だったところの文字コードの値の差」が表示されます。違う文字だった箇所のASCIIコードの値が左のほうが小さければ負、右のほうが小さければ正が返されます。
注釈
| ↑1 | 詳しく言うと、s1のほうが辞書順序(正確に言うとASCIIコードの値で比較している、なので大文字は小文字よりも先と判定される)で先にある場合は負の値を、s2のほうが辞書順序で先にある場合は正の値を返します。 |
|---|
関連広告・スポンサードリンク