スポンサードリンク
こんにちは、ももやまです。
今回は基本情報にもよく出てくる配列とリストについて説明していきたいと思います。
目次
スポンサードリンク
1.配列とは
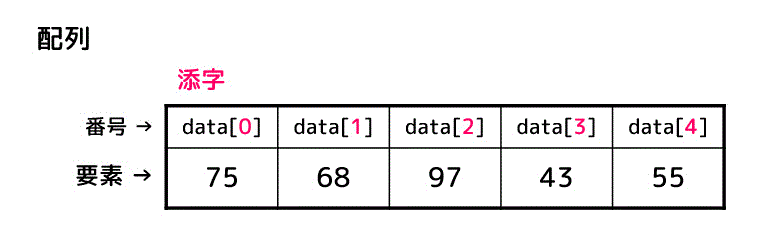
配列は、下のように同じデータ型の要素を番号順に並べたものを表します。
また、この番号は添字(インデックス)と呼ばれます。

添字は0スタートの場合と1スタートの場合がありますが、C言語を含む多くの言語は0スタートです。
配列の場合、指定したい要素を添字で指定します。
例えば、上の図の配列で2番目を指定すると97の要素を得ることができます。

また、添字を数字ではなく、2i + j のような数式で指定することもできます。
例えば、i = 3, j = 2 のときに 2i + j 番目を指定すると、8番目を計算してくれます。
また配列を2重に組み合わせて2次元配列をつくることができます。
2次元配列のイメージは、下のような行と列からできた表です。

基本的に2次元配列 a[i][j] の1つ目の添字 i が行、2つ目の添字 j が列を表します。
他に2次元配列で表現できるものとして、行列やビンゴカードなどがあります。
スポンサードリンク
2.リストとは
リストは、「要素」と「次のデータを指し示すポインタ(場所)」の2つからなるデータが数珠のようにつながっているデータ構造です。

例えば20番地のアドレスのデータには、要素である「75」と「次のデータのポインタ(40番地)」が入っています。
リストの場合、要素を探すために先頭からポインタをたどる必要があります。

例えば、上の図のリストで97の要素がある60番地のデータを探したい場合、「20番地→40番地→60番地」のように順番にたどることで目的の60番地のデータを見つけることができます。
リストには次のデータのポインタだけを持つ単方向リスト以外にも、前のデータのポインタも持つ双方向リスト、末尾と先頭のデータを連結させることで環状線のようにぐるぐるできる環状リストがあります。

単方向リスト以外にもこんなリストがあるんだな~ってことがわかればOKです。
なお、単にリストとだけ書いてあった場合は「単方向リスト」を表していると思ってください。
スポンサードリンク
3.配列とリストの比較
配列とリストはともに同じ型のデータですが、どちらも一長一短で使い分けられます。
(1) データのアクセス
データのアクセスの場合、配列の方が優れています。
配列は、添字(番号、インデックス)で要素を指定できるのでワンステップで要素を指定することができます。
一方リストは先頭からリストをたどっていくことでしか要素を探せないため、最大で要素数ステップの時間がかかってしまいます。
(2) データの追加・削除
データの追加、削除はリストが優れています。
配列は、データを追加 or 削除するために、後ろにあるデータを下のようにずらす必要があります。そのため、ずらすデータの数だけ余計に処理時間がかかります。
配列の追加

配列の削除

リストでは、次のデータを指し示すポインタを下のように少し書き換えるだけでデータの追加、削除を行うことができます。そのため、後ろのデータに関係なく数ステップで処理ができます。
リストの追加

リストTの削除

(3) 格納領域
格納領域も、リストの方が優れています。
配列の場合、最初に int data[100]; のように格納領域を指定するため、使わない無駄な領域が発生してしまいます。
一方リストはポインタだけで前後関係を表しているので、動的に拡張領域を変更することができ、無駄な領域が発生しません。
頻繁にデータにアクセスするようであれば配列を、頻繁にデータを書き換える場合であれば連結リストのように使い分けると効率がよくなります。
念のため、データのアクセス、データの書き換えをオーダー表記で表したものを下に示しておきます。
| 操作内容 | 配列 | リスト |
|---|---|---|
| データアクセス | \( O(1) \) | \( O(n) \) |
| データ挿入/削除 | \( O(n) \) | \( O(1) \) |
オーダー表記を用いた計算時間の表現方法については下の記事でわかりやすく説明しているので、下の記事をご覧ください。
4.配列とリストの操作実装
では、配列、リストの定義、要素の追加、要素の削除をC言語で実装したものを下に記します。
なお、配列・リストの中身は上で紹介した図と同じにしています。
配列
配列を定義し、要素を追加・削除する過程をプログラムで書くと下のようになります。
forループの向きに気を付けましょう。向きを間違えると正しく追加 or 削除されません。
#include <stdio.h>
void printArray(int a[], int n) {
for(int i = 0; i < n; i += 1) {
printf("%d ",a[i]);
}
printf("\n");
}
int main() {
int a[5] = {75,68,97,43,55}; // 配列の定義
int n = 5; // 要素数
// 2番目(97) と 3番目(43) の間に要素50を追加
for(int i = n - 1; i >= 3; i -= 1) {
a[i+1] = a[i];
}
a[3] = 50;
n += 1;
// 追加終了 forループの向き注意
printArray(a,n); // 75 68 97 50 43 55
// 2番目の要素を削除
for(int i = 2; i < n - 1; i += 1) {
a[i] = a[i+1];
}
n -= 1;
// 削除終了 forループの向き注意
printArray(a,n); // 75 68 50 43 55
return 0;
}
挿入、削除にforループを使うため、後ろにある要素数分だけ余計なステップ数がかかってしまいます。
リスト
リストは、下のような構造体で定義することができます。
struct LIST {
int data; // 要素
struct LIST *next; // 次のデータの場所(ポインタ)
} ; // ここにもセミコロンあるよ!
構造体 LIST の next には、次のデータがある「場所」が入るので、ポインタ変数*1で宣言します。
意外と定義するときに最後のセミコロン ; を忘れやすいので気をつけましょう。
#include <stdio.h>
#define N 9
struct LIST {
int data; // 要素
struct LIST *next; // 次のデータの場所(ポインタ)
} ; // ここにもセミコロンあるよ!
void printList(struct LIST *p) {
while(p != NULL) {
printf("%d ",p->data);
p = p->next; // 配列でいう i++ と同じ
}
printf("\n");
}
int main() {
struct LIST p0,p1,p2,p3,p4,p5;
struct LIST *top;
p0.data = 75;
p0.next = &p1;
p1.data = 68;
p1.next = &p2;
p2.data = 97;
p2.next = &p3;
p3.data = 43;
p3.next = &p4;
p4.data = 55;
p4.next = NULL;
top = &p0; // リストの先頭場所を代入
printList(top); // 75 68 97 43 55
// p2(97)とp3(43)の間に要素「50」を追加
p5.data = 50;
p5.next = &p3;
p2.next = &p5;
// 追加終了 要素数関係なしに3ステップで可能!
printList(top); // 75 68 97 50 43 55
// p2 のデータを削除
p1.next = p1.next->next;
// 削除終了 要素数関係なしに2ステップで可能!
printList(top); // 75 68 50 43 55
return 0;
}
for文を使わずにポインタだけで挿入、削除ができるので後ろにある要素数に関係なしに数ステップで処理ができます。
ポインタがいまいちよくわかっていない…… という人は下の記事にわかりやすくまとめているのでこの機会に復習しましょう!
5.練習問題
では、配列とリストに関する基本情報、応用情報の問題で練習してみましょう。
練習1
データ構造の一つであるリストは、配列を用いて実現する場合と、ポインタを用いて実現する場合とがある。配列を用いて実現する場合の特徴はどれか。ここで、配列を用いたリストは、配列に要素を連続して格納することによって構成し、ポインタを用いたリストは、要素から次の要素へポインタで連結することによって構成するものとする。
[基本情報技術者平成29年春期 午前問4]ア:位置を指定して、任意のデータに直接アクセスすることができる。
イ:並んでいるデータの先頭に任意のデータを効率的に挿入することができる。
ウ:任意のデータの参照は効率的ではないが、削除や挿入の操作を効率的に行える。
エ:任意のデータを別の位置に移動する場合、隣接するデータを移動せずにできる。
練習2
配列と比較した場合の連結リストの特徴に関する記述として、適切なものはどれか。
[基本情報技術者平成21年春期 午前問6]
ア:要素を更新する場合、ポインタを順番にたどるだけなので、処理時間は短い。
イ:要素を削除する場合、削除した要素から後ろにあるすべての要素を前に移動するので、処理時間は長い。
ウ:要素を参照する場合、ランダムにアクセスできるので、処理時間は短い。
エ:要素を挿入する場合、数個のポインタを書き換えるだけなので、処理時間は短い。
練習3
2次元の整数型配列 a の各要素 a(i,j) の値は,2i+j である。このとき、a(a(1,1)×2,a(2,2)+1) の値は幾つか。
[基本情報技術者平成28年春期 午前問6]
ア:12
イ:13
ウ:18
エ:19
練習4
リストを二つの1次元配列で実現する。配列要素 box[i] と next[i] の対がリストの一つの要素に対応し、box[i] に要素の値が入リ、next[i] に次の要素の番号が入る。配列が図の状態の場合、リストの3番目と4番目との間に値が H である要素を挿入したときの next[8] の値はどれか。ここで、next[0] がリストの先頭(1番目)の要素を指し、next[i] の値が0である要素はリストの最後を示し、next[i] の値が空白である要素はリストに連結されていない。
[基本情報技術者平成30年春期 午前問6]

ア:3
イ:5
ウ:7
エ:8
練習5
n個の要素x[1]、x[2]、…、x[n]から成る連結リストに対して、新たな要素x[n+1]の末尾への追加に要する時間をf(n)とし、末尾の要素 x[n] の削除に要する時間をg(n)とする。nが非常に大きいとき、実装方法1と実装方法2における \( \frac{ g(n) }{ f(n) } \) の挙動として、適切なものはどれか。
[応用情報技術者平成21年秋期 午前問5]
〔実装方法1〕
先頭のセルを指すポインタ型の変数frontだけをもつ。

〔実装方法2〕
先頭のセルを指すポインタ型の変数frontと、末尾のセルを指すポインタ型の変数rearを併せもつ。

選択肢

6.練習問題の答え
解答1
解答:ア
配列の特徴は、
- 任意のデータにワンステップで直接アクセスできる
- 削除、挿入は後ろのデータをずらす必要があるため、処理に時間がかかる
- あらかじめ領域を定義する必要がある
の3点です。以上の3点を踏まえると、答えはアとなります。
ア:正しい。添字で位置を指定し、任意のデータにアクセスできる。
イ:データの先頭に挿入するためには、2番目以降のデータをすべてずらす必要があり、非効率的。
ウ:任意のデータの参照は効率的にできるし、削除や挿入は後ろのデータをずらす必要がある。大間違い。
エ:データを移動する際には、他のデータの場所を動かす必要あり。間違い。
解答2
解答:エ
連結リストの特徴は、
- ポインタをたどる必要があるため、データのアクセスは遅い
- 削除、挿入はポインタを少し書き換えるだけでOKなので効率的に処理可能
- 動的に領域を使える
の3点です。以上の3点を踏まえると、答えはエとなります。
ア:ポインタを順番にたどるから処理時間が長くなってしまいます。なのでNG。
イ:連結リストの場合、削除する場合はポインタを少し書き換えるだけでOKなのでこれも誤り。
ウ:ランダムに要素にアクセスできるのは配列なのでNG。
エ:正解の選択肢。
解答3
解答:エ
a(a(1,1)×2,a(2,2)+1) = a(6,7) = 12 + 7 = 19
より答えは19。
解答4
まず問題文をよく読みましょう。リストの最初は next[0] なので0ではなく1です。
4番目までのデータをおとなしく順番にたどっていきましょう。
すると、
1 → 5 → 3 → 7
となりますね。3番目と4番目の間に H の要素の番号が来るので、順番は
1 → 5 → 3 → 8 → 7
となりますね。next[8] の値は、8の次にたどる要素の番号なので、答えは7となり、ウとなります。
解答5
解答:イ
[実装方法1(先頭を指すポインタのみ)]の場合データの追加は、先頭から末尾までデータをたどっていく必要があるので n ステップが必要。
データの削除も、先頭から末尾の1つ前のデータをたどり、末尾のデータを削除するのでこちらも n ステップが必要。
よって、 g(n) / f(n) はほぼ1となる。
[実装方法2(先頭を指すポインタと末尾を指すポインタ)]の場合データの追加は、末尾を指すポインタを使うことで数ステップで実現可能。
一方データの削除は、末尾の1つ前のポインタをたどる必要がある。末尾の1つ前のポインタは「末尾を指すポインタ」からたどれないので約 n ステップかけてたどる必要あり。
よって、 g(n) / f(n) はほぼnとなる。
よって答えはイ。
7.さいごに
今回は、基本情報・応用情報に出てくるデータ構造「配列」・「連結リスト」についてまとめていきました。
配列、連結リストは基本情報や応用情報で頻出するだけでなく、「データ構造とアルゴリズム」分野の基礎となるので必ず頭にいれておきましょう。
*1:ポインタ変数で宣言することで、場所を記憶する変数として使うことができます。
関連広告・スポンサードリンク




![うさぎでもわかる計算機システム Part05 論理回路の基本編 [基本情報対応]](https://www.momoyama-usagi.com/wp-content/uploads/2021/05/20190627094337-1-150x150.gif)