スポンサードリンク
こんにちは、ももやまです。
今回はデータベースの正規化について簡単にまとめました。
目次
スポンサードリンク
1.候補キー・主キー
正規化について書く前にまずは候補キーと主キーについての説明をしておきます。
候補キーは、データのレコード(タプル・データの集まり)を1つに特定できるようなデータ列のことを表します。候補キーは2つ以上ある可能性があります。
主キーは、上で説明した候補キーの中から最適な組み合わせを1つだけ選んだものです。多くの場合、学生番号、受験番号、IDなどのアルファベットや数字からなる簡潔なものになります。
主キーを満たす条件としては、
- レコード(タプル)を1つに特定できること(重複NG)
- NULLにならないこと
- 候補キーの中から最も適した1通りの組み合わせである
(主キーが2つ以上あることもあるので注意)
この3つを両方満たして主キーと言うことができます。
では、実際にリレーション(データ表)を見ていきましょう。
リレーション1 とある駅の連動するゲームの情報を管理したリレーション
このリレーションだと主キーになるのはどれでしょう。

この場合だと、ユーザーIDさえあれば他の4つのデータをすべて特定することができますね。
なので、主キーは「ユーザーID」と言うことができます。
(他の4つのデータは重複する可能性があります。)
リレーション2 主キーが複数の場合
次に主キーが複数である場合を見ていきましょう。

生徒IDがあればデータが特定できると思ったそこのあなた!
生徒IDも重複してしまっているので生徒IDだけではデータを特定することができません……。
この場合、主キーは生徒IDと模試IDの2つの組み合わせである必要があります。
(候補キーを組み合わせて1つの主キーを作っていると考えてください。)
なお、これ以降の説明では、主キーの項目はよりグレーにしています。
スポンサードリンク
2.正規系・正規化
ではいよいよ正規化に入りたいと思います。
多くの場面では第3正規系まで理解できていればOKなので今回は非正規系、第1~3正規系について解説をします。
1.非正規系(非正規系→第1正規系)
非正規系はデータが複数行にまたがっているデータや、(下の例ではないですが)1つの行に2つ以上のデータが入っているような状態のようなものを表します。

この状態ではデータベースに入れることすらできないのでまずは、データを重複させないようにし、1つの行に1つのデータが入っているようにしましょう。
これで第1正規系に正規化をすることができました。

2.第1正規系(第1正規系→第2正規系以上へ)
しかし、まだ正規化は不十分です。
第1正規系からさらに正規化を行うためには、リレーションの主キーを考える必要があります。
今回の主キーは「空港コード」だけではなく「商品ID」も該当しますね。
「空港キー」だけではデータ行の特定ができません(同じ空港コードが登録されているから)。
第1正規系かどうかを判定するのに大切なのは主キーの一部だけを使ってわかるカラムが存在するかです。

たとえば、「空港名」・「所在地」は空港コードだけに依存しますね(商品IDは全く関係ない)。
また、輸送商品も「商品ID」だけを見ることでわかりますね。
このように、主キーのすべてではなく、一部を見ただけでデータ行(レコード)を特定できるようなものがある(このようなものを部分関数従属と言います)場合、第1正規系止まりになってしまいます。
第1正規系からさらに正規化するには、主キーの一部を見ただけでデータ行が特定できるようなものを分離する必要があります。今回の場合は、
- 空港コードのみに依存するもの [左上]
- 商品IDに依存するもの [左下]
- 両方に依存するもの [右](注意!!)
の3つに分解する必要があります。分解を行うと、下のようになります。

正規化における注意!!
第1正規系を第2,第3と正規化する場合に注意したいことが、正規化を行っても正しくデータをもとに戻せるように正規化を行って下さい。
たとえばこの表(先程のリレーションから「輸送ID」を抜いたもの)を正規化(第1→第2)してみましょう。

今回の場合は、
- 空港コードのみに依存するもの
- 商品IDに依存するもの
の2つしか存在しませんね。だからといって分解を下の2つにしないでください。

この2つだけだと、空港コードと商品IDの対応付けがわからないのでデータをもとに戻すことができませんね。なので、この場合は、
- 空港コードのみに依存するもの [左上]
- 商品IDに依存するもの [左下]
- 両方に依存するもの(空港コードと商品IDの対応付け)
の3つになるので注意しましょう。

3.第2正規系(第2正規系→第3正規系以上へ)
これで少なくとも第2正規系以上にはなりますね。
しかし、第2正規系でももう少し正規化が必要です。
たとえばこのリレーションを見てみましょう。このリレーションは本当に第2正規系以上でしょうか。

まずは、この表の主キーを考えましょう。
今回の場合は、処理ID1つがあれば他のデータが特定できますね。
なので、主キーは処理ID1つとなります。
また、今回は主キーの一部を使って特定できるデータ(部分関数従属)はありませんね(そもそも主キー1つですし…)。なので第2正規系以上なことがわかります。
(主キーが1つの場合は基本的に第2正規系以上が確定すると思ってもらってOKです)
第3正規系の条件としては、
- 第2正規系の条件をクリアしている
- 主キー以外からも依存しているカラムが存在しないこと(主キー以外から特定できるカラムが存在しないこと)
の2つとなります。
たとえば、この表では、店舗名は直接的には処理IDには依存していませんね。
表を見ると、店舗名は店舗ID側に依存しています。
言い換えると、処理IDから店舗ID、店舗IDから店舗名とすることで処理IDから店舗名が特定することができます(推移的関数従属といいます)。

よって、このリレーションは第2正規系どまりであることがわかります。
なので、第3正規系にしてあげましょう。
第3正規系にする場合には、主キー以外から特定できるものを分離してあげます。
今回の場合は、店舗IDから店舗名を分離できるので、店舗名だけを分離します。
分離先のリレーションは、店舗IDから店舗名を1つに特定できるため、主キーは店舗IDとなります。

すると、このように分離することができます。
先程と同じく、正規化を行っても正しくデータをもとに戻せるように正規化を行って下さい。
たとえば左側の表から店舗名でだけでなく店舗IDまで分離してしまうと、店舗IDと店舗名の対応付けができなくなり、正しくデータが戻せなくなります。
スポンサードリンク
3.第?正規系かの判定方法
第3正規系までの説明が終わったので、データベースの正規系を見分ける方法を簡潔にまとめました。
上から順番に確認してください。
- データが複数行にまたがっていない
- 1つの行に2つ以上のデータが入っていない
この2つを満たしていなければ非正規系です。
- 複数ある主キーのうちの一部を見ただけでデータ行(レコード)を特定できるカラム(列)がない(部分関数従属がないこと)
この条件を満たしていなければ第1正規系止まりです。
なお、主キーが1つの場合は自動的にこの条件はクリアします(第2正規系確定)。
- 主キー以外からも依存しているカラムが存在しない(推移的関数従属がないこと)
この条件を満たしていなければ第2正規系止まり、満たしていれば第3正規系以上となります。
4.正規化されていないことにより発生する問題
正規化を行うことの大きな理由として、異常事態を防ぐことが挙げられます。
第3正規系まで正規化されていないと様々な問題が発生する確率が上がります。
実際にどのような問題が生じるかを第3正規系の目前である第2正規系のデータでみてみましょう。
たとえば、
- 処理ID43001を消すと名古屋支店が消滅する
- 新しく店舗名ができても実際に処理を行い、処理IDが追加されるまでは新しい店舗名をデータベースを追加できない
- 店舗名が変更されたら関係のあるデータをすべて修正する必要があり、修正を忘れてしまう可能性がある
などの問題が発生します。
そのため、(少なくとも)第3正規系にすることで異常事態が起こる確率を防ぐのです。
(非正規系は論外(問題ありまくり)、第1正規系でも第2正規系のような問題が発生します。)
5.練習問題
では実際にに練習しましょう。
練習1
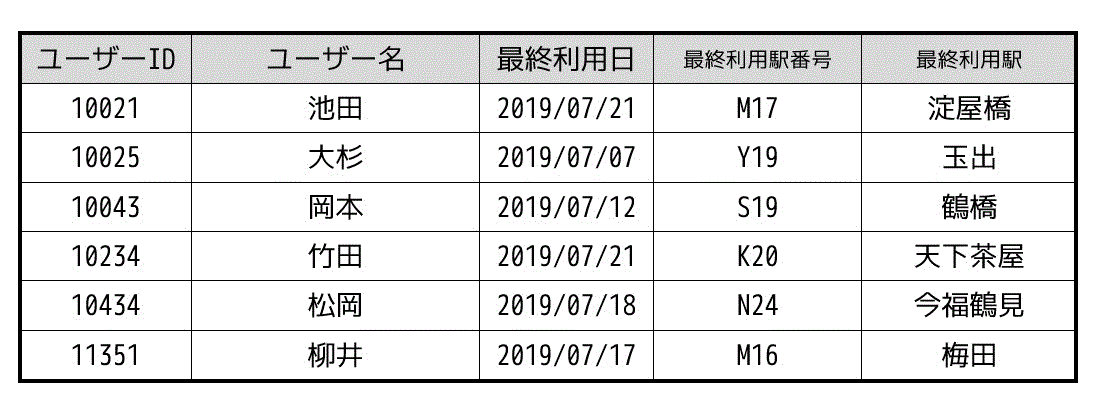
次のようなリレーションがある。
なお、これはデータの一部であり、他にも様々なデータが登録されている。
なお、ユーザーIDだけは重複しない。
(1) このリレーションは第何正規系ですか?
(2) (1)より1つ以上高次の正規系にしなさい。
解答1
(1)
主キーは「ユーザーID」ただ1つですね。
なので自動的に第2正規系以上ですね(主キーが1つなので主キーの一部を使って特定できるデータがあるわけない)。
しかし、最終利用駅は最終利用駅番号から特定することができますね(最終利用駅は最終利用駅番号に依存)。
なので、「ユーザーIDから最終利用駅番号を特定」・「最終利用駅番号から最終利用駅を特定」という推移従属があり、第3正規系と言うことはできません。
なので答えは第2正規系となります。
(2)
推移従属を取り除きます。
最終利用駅は最終利用番号からわかるので分離します。

練習2
次のようなリレーションがある。
(1) このリレーションは第何正規系ですか?
(2) (1)より1つ以上高次の正規系にしなさい。
解答2
(1)
主キーは生徒IDと模試IDの組み合わせでしたね。
たとえば、生徒名は生徒IDだけに依存し、模試IDには一切依存しませんね。
なので、主キーの一部を見るだけで生徒名が特定できてしまいます(部分関数従属がある)。
また、模試名も模試IDだけに依存し、生徒IDは一切関係がありませんね。
よって第1正規系です(非正規系ではないのは見たらわかるので省略しています)。
(2)
依存があるデータを隔離することで正規化を行います。
- 生徒IDだけでわかるカラム(主キーは生徒ID)
- 模試IDだけでわかるカラム(主キーは模試ID)
- 両者ともないとわからないカラム(主キーは生徒ID・模試ID)
の3つに分離をしてください。

練習3
つぎの「受注明細」表は、どのレベルまでの正規形の条件を満足しているか。ここで、よりグレーになっていスキーマ(列タイトル)は主キーを表す。
[応用情報技術者平成29年春期 午前問27]
ア:第1正規系
イ:第2正規系
ウ:第3正規系
エ:第4正規系
解答3
主キーは「ユーザーID」・「明細番号」の2つですね。
非正規系ではないのは明らか(第1正規系の条件クリア)なので第2正規系の条件を満たしているか確認します。
「商品コード」・「商品名」・「数量」いずれも2つの主キーがないと特定できませんね。
なので、第2正規系の条件はクリアしています。
つぎに、第3正規系の条件をクリアしているか確認します。
商品名は商品コードから特定することができますね(商品名は商品コードに依存)。
なので、「2つの主キーから商品コードを特定」・「商品コードから商品名を特定」という推移従属があり、第3正規系と言うことはできません。
なので答えは第2正規系となります。
解答3のおまけ
ついでに第2正規系の上のデータを正規化して第3正規化にしてみましょう。
商品名は商品コードに依存しているので、商品名を切り離して別の表にしてあげます。
すると、以下の2つの表に分離することができます。

商品の表の主キーは商品コードです(商品コードから商品名を特定可)。
練習4
次のようなリレーションがある。次の問いに答えなさい。
[基本情報技術者平成21年春期 午前問32(改題)]
(実際の出題では、表は与えられずにどの項目が繰り返しデータであるかが与えられているだけでした。)

(1) このリレーションの主キーの組み合わせを答えなさい。
(2) このリレーションはどのレベルまでの正規形の条件を満足しているか。
ア:第1正規系
イ:第2正規系
(3) このリレーションを第3正規系にしたものとして正しいものはどれか。
なお、表のデータの中身は省略している(スキーマだけを表示している)。


解答4
(1)
主キーは従業員番号だけではありませんね。
従業員番号だけではデータを特定できません。
特定するためには「技能コード」も必要ですね。
なので主キーの組み合わせは「授業員番号」・「技能コード」となります。
(2)
第1正規系なのは明らかなので第2正規系かどうかを確認します。
従業員名は従業員番号から特定ができます(技能コードがなくても特定可能)。
技能名は技能コードから特定ができますね(従業員番号がなくても特定可能)。
主キーの一部を見るだけで特定できるデータがあるため(部分関数従属がある)、
第1正規系となり、答えはアとなります。
(3)
さらに高次のデータが必要です。
- 従業員コードだけで特定可能なデータは「従業員名」(主キーは従業員番号)
- 技能コードだけで特定可能なデータは「技能名」(主キーは技能コード)
- 両者の主キーで特定可能なデータは「技能経験年数」(主キーは従業員番号・技能コードの両者)
ですね。なので、答えはウとなります。
6.さいごに
今回はデータベースにおける正規化についてまとめました。
第3正規系までの理解しておけば試験などで困ることは少ないため、まずは第3正規系までを理解しましょう!
関連広告・スポンサードリンク